Was ist das Ziel dieses Crashkurses?
Ziel dieses Crashkurses ist es, einen Überblick über die Assembler-Programmierung zu geben, insbesondere für die Teilnehmer von BS, die noch keine Assemblerkenntnisse besitzen.
Wir bilden uns nicht ein, dass ihr am Ende komplexe Assemblerprogramme schreiben könnt, aber das braucht ihr schließlich auch nicht. Wir hoffen aber, dass ihr auf diese Weise zumindest eine gewisse Vorstellung davon erhaltet, wie ein Hochsprachenprogramm in Assembler aussieht und bei entsprechender Hilfestellungen auch selbst ganz kleine Assemblerfunktionen schreiben könnt.
Die verschiedenen Konzepte werden am Beispiel des x86-Prozessors erläutert. Diese Prozessorreihe stammt von der Firma Intel und steckt direkt oder als Nachbau u. a. in jedem PC. Die verwendete Notation entspricht dem Netwide Assembler NASM, der auch bei der Entwicklung den Übungsbetriebssystems OOStuBS Verwendung findet.
Den "Rahmen" eines Assemblerprogramms erklären wir hier nicht, den schaut ihr euch am besten an einer Assemblerdatei ab.
Was ist ein Assembler?
Ein Assembler ist genaugenommen ein Compiler, der den Code eines "Assemblerprogramms" in Maschinensprache, d. h. Nullen und Einsen übersetzt. Anders als ein C-Compiler hat es der Assembler jedoch sehr einfach, da (fast immer) einer Assembleranweisung genau eine Maschinensprachenanweisung entspricht. Das Assemblerprogramm ist also nur eine für Menschen (etwas) komfortablere Darstellung des Maschinenprogramms:
Statt
000001011110100000000011
schreiben zu müssen, kann der Programmierer die Assembleranweisung
add ax,1000
verwenden, die (bei den x86-Prozessoren) genau dasselbe bedeutet:
| symbolische Bezeichnung | Maschinencode |
|---|---|
| add ax | 00000101 |
| 1000 (dez.) | 0000001111101000 |
Zusätzlich vertauscht der Assembler noch die Reihenfolge der Bytes des Offsets:
| add ax | low-Byte | high-Byte |
|---|---|---|
| 00000101 | 11101000 | 00000011 |
Im üblichen Sprachgebrauch wird unter "Assembler" jedoch weniger der Compiler verstanden, als die symbolische Notation der Maschinensprache. add eax,1000 ist dann also eine Assembleranweisung.
Was kann ein Assembler?
Ein Assembler kann eigentlich sehr wenig, nämlich nur das, was der Prozessor direkt versteht. Die ganzen schönen Konstrukte höherer Programmiersprachen, die dem Programmierer erlauben, seine Algorithmen in verständliche, (ziemlich) fehlerfreie Programme zu übertragen, fehlen:
- keine komplexen Anweisungen
- keine komfortablen
for-,while-,repeat-until-Schleifen, sondern fast nurgotos - keine strukturierten Datentypen
- keine Unterprogramme mit Parameterübergabe
- ...
Beispiele:
Die C-Anweisung
summe = a + b + c + d;
ist für einen Assembler zu kompliziert und muss daher in mehrere Anweisungen aufgeteilt werden. Der x86-Assembler kann immer nur zwei Zahlen addieren und das Ergebnis in einer der beiden verwendeten "Variablen" (Akkumulatorregister) speichern. Das folgende C-Programm entspricht daher eher einem Assemblerprogramm:
summe = a; summe = summe + b; summe = summe + c; summe = summe + d;
und würde beim x86-Assembler so aussehen:
mov eax,[a] add eax,[b] add eax,[c] add eax,[d] mov [summe], eax
Einfache
if-then-else-Konstrukte sind für Assembler auch schon zu schwierig:if (a == 4711) { ... } else { ... }und müssen daher mit Hilfe von
gotos ausgedrückt werden:if (a != 4711) goto ungleich gleich: ... goto weiter: ungleich: ... weiter: ...Im x86-Assembler sieht das dann so aus:
cmp eax,4711 jne ungleich gleich: ... jmp weiter ungleich: ... weiter: ...Einfache Zählschleifen werden vom x86-Prozessor schon besser unterstützt. Das folgende C-Programm
for (i=0; i<100; i++) { summe = summe + a; }sieht im x86-Assembler etwa so aus:
mov ecx,100 schleife: add eax,[a] loop schleifeDer Loop-Befehl dekrementiert implizit das
ecx-Register (ecxist das **e**xtended **c**ounter register) und führt den Sprung nur aus, wenn der Inhalt desecx-Registers anschließend nicht 0 ist.
Was ist ein Register?
In den bisher genannten Beispielen wurden anstelle der Variablennamen des C-Programms stets die Namen von Registern verwendet. Ein Register ist ein winziges Stückchen Hardware innerhalb des Prozessors, das beim x86 und höher bis zu 32 Bits, also 32 Ziffern im Bereich 0 und 1 speichern kann.
Der x86 besitzt folgende Register, die sich noch in verschiedene Gruppen einteilen lassen, je nachdem welche Funktion sie in der Maschiene übernehmen.
| Name | Bemerkung |
|---|---|
| Allgemein verwendbare Register | |
eax | allgemein verwendbar, spezielle Bedeutung bei Arithmetikbefehlen |
ebx | allgemein verwendbar |
ecx | allgemein verwendbar, spezielle Bedeutung bei Schleifen |
edx | allgemein verwendbar |
ebp | Basepointer |
esi | Quelle (eng: source) für Stringoperationen |
edi | Ziel (eng: destination) für Stringoperationen |
esp | Stackpointer |
| Segmentregister | |
cs | Codesegment |
ds | Datensegment |
ss | Stacksegment |
es | beliebiges Segment |
fs | beliebiges Segment |
gs | beliebiges Segment |
| Spezialregister | |
eip | Instruction Pointer |
eflags | Flags register |
Da der x86 Prozessor abwärtskompatibl zu vielen früheren Versionen der Architektur sind, kann man bei einigen Registern über spezielle Namen nur auf Teile der Register zugreifen. Die unteren beiden Bytes der Register eax, ebx, ecx und edx haben eigene Namen, beim eax-Register sieht das so aus:

Was ist Speicher?
Meistens reichen die Register nicht aus, um ein Problem zu lösen. In diesem Fall muss auf den Hauptspeicher des Computers zugegriffen werden, der erheblich mehr Information speichern kann. Für den Assemblerpogrammierer sieht der Hauptspeicher wie ein riesiges Array von Registern aus, die je nach Wunsch 8, 16 oder 32 Bits "breit" sind. Die kleinste adressierbare Einheit ist also ein Byte (= 8 Bits). Daher wird auch die Größe des Speichers in Bytes gemessen. Um auf einen bestimmten Eintrag des Arrays "Hauptspeicher" zugreifen zu können, muss der Programmierer den Index, d. h. die Adresse des Eintrages kennen. Das erste Byte des Hauptspeichers bekommt dabei die Adresse 0, das zweite die Adresse 1 usw.
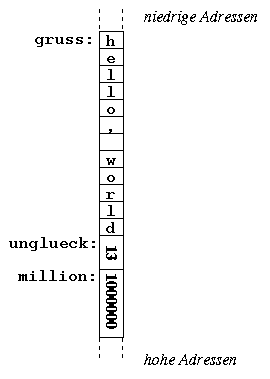
In einem Assemblerprogramm können Variablen angelegt werden, indem einer Speicheradresse ein Label zugeordnet und dabei Speicherplatz in der gewünschten Größe reserviert wird.
[SECTION .data]
gruss: db 'hello, world'
unglueck: dw 13
million: dd 1000000
[SECTION .text]
mov ax,[million]
...
| 
|
Was ist ein Stack (deutsch: Stapel)?
Nicht immer will man sich ein neues Label ausdenken, nur um kurzfristig den Wert eines Registers zu speichern; beispielsweise, weil man das Register für eine bestimmte Anweisung benötigt, den alten Wert aber nicht verlieren möchte. In diesem Fall wünscht man sich etwas wie einen Schmierzettel. Den bekommt man mit dem Stack. Der Stack ist eigentlich nichts weiter als ein Stück des Hauptspeichers, nur dass dort nicht mit festen Adressen gearbeitet wird, sondern die zu sichernden Daten einfach immer oben drauf geschrieben (push) bzw. von oben heruntergeholt werden (pop). Der Zugriff ist also ganz einfach, vorausgesetzt man erinnert sich daran, in welcher Reihenfolge die Daten auf den Stapel gelegt wurden. Ein spezielles Register, der Stackpointer esp, zeigt stets auf das oberste Element des Stacks. Da push und pop immer nur 32 Bits auf einmal transferieren können, ist der Stack in der folgenden Abbildung als vier Bytes breit dargestellt.

Adressierungsarten
Die meisten Befehle des x86 können ihre Operanden wahlweise aus Registern, aus dem Speicher oder unmittelbar einer Konstante entnehmen. Beim mov-Befehl sind (u. a.) folgende Formen möglich, wobei der erste Operand stets das Ziel und der zweite stets die Quelle der Kopieraktion angeben:
- Registeradressierung: Der Wert eines Registers wird in ein anderes übertragen.\
mov ebx,edi - Unmittelbare Adressierung: Die Konstante wird in das Register übertragen.\
mov ebx,1000 - Direkte Adressierung: Der Wert, der an der angegebenen Speicherstelle steht, wird in das Register übertragen.\
mov ebx,[1000] - Register-indirekte Adressierung: Der Wert, der an der Speicherstelle steht, die durch das zweite Register bezeichnet wird, wird in das erste Register übertragen.\
mov ebx,[eax] - Basis-Register-Adressierung: Der Wert, der an der Speicherstelle steht, die sich durch die Summe des Inhalts des zweiten Registers und der Konstanten ergibt, wird in das erste Register übertragen.\
mov eax,[10+esi]
Anmerkung: Wenn der x86-Prozessor im Real-Mode betrieben wird (z. B. bei der Arbeit mit dem Betriebssystem MS-DOS), werden Speicheradressen durch ein Segmentregister und einen Offset angegeben. Bei der Veranstaltung Betriebssysteme ist das nicht nötig (sondern sogar falsch), weil OOStuBS im Protected-Mode läuft und die Segmentregister von uns bereits für euch initialisiert wurden.
Prozeduren
Aus den höheren Programmiersprachen ist das Konzept der Funktion oder Prozedur bekannt. Der Vorteil dieses Konzeptes gegenüber einem goto besteht darin, dass die Prozedur von jeder beliebigen Stelle im Programm aufgerufen werden kann und das Programm anschließend an genau der Stelle fortgesetzt wird, die nach dem Prozeduraufruf folgt. Die Prozedur selbst muss nicht wissen, von wo sie aufgerufen wurde und wo es hinterher weiter geht. Das geschieht irgendwie automatisch. Aber wie?
Die Lösung besteht darin, dass nicht nur die Daten des Programms, sondern auch das Programm selbst im Hauptspeicher liegt und somit zu jeder Maschinencodeanweisung eine eigene Adresse gehört. Damit der Prozessor ein Programm ausführt, muss sein Befehlszeiger auf den Anfang des Programms zeigen, also die Adresse der ersten Maschinencodeanweisung in das spezielle Register des Befehlszeigers (instruction pointer eip) geladen werden. Der Prozessor wird dann den auf diese Weise bezeichneten Befehl ausführen und im Normalfall anschließend den Inhalt des Befehlszeigers um die Länge des Befehls im Speicher erhöhen, so dass er auf die nächste Maschinenanweisung zeigt. Bei einem Sprungbefehl wird der Befehlszeiger nicht um die Länge des Befehls, sondern um die angegebene relative Zieladresse erhöht oder erniedrigt.
Um nun eine Prozedur oder Funktion (in Assembler dasselbe) aufzurufen, wird zunächst einmal wie beim Sprungbefehl verfahren, nur dass der alte Wert des Befehlszeigers (+ Länge des Befehls) zuvor auf den Stack geschrieben wird. Am Ende der Funktion genügt dann ein Sprung an die auf dem Stack gespeicherte Adresse, um zu dem aufrufenden Programm zurückzukehren.
Beim x86 erfolgt das Speichern der Rücksprungadresse auf dem Stack implizit mit Hilfe des call-Befehls. Genauso führt der ret-Befehl auch implizit einen Sprung an die auf dem Stack liegende Adresse durch:
; ----- Hauptprogramm -----
;
main: ...
call f1
xy: ...
; ----- Funktion f1
f1: ...
ret

Wenn die Funktion Parameter erhalten soll, werden diese üblicherweise ebenfalls auf den Stack geschrieben, natürlich vor dem call-Befehl. Hinterher müssen sie natürlich wieder entfernt werden, entweder mit pop, oder durch direktes Umsetzen des Stackpointers:
push eax ; zweiter Parameter fuer f1 push ebx ; erster Parameter fuer f1 call f1 add esp,8 ; Parameter vom Stack entfernen
Um innerhalb der Funktion auf die Parameter zugreifen zu können, wird üblicherweise der Basepointer ebp zu Hilfe genommen. Wenn er gleich zu Anfang der Funktion gesichert und dann mit dem Wert des Stackpointers belegt wird, kann der erste Parameter immer über [ebp+8] und der zweite Parameter über [ebp+12] erreicht werden, unabhängig davon, wieviele push- und pop-Operationen seit Beginn der Funktion verwendet wurden.
f1: push ebp
mov ebp,esp
...
mov ebx,[ebp+8] ; 1. Parameter in ebx laden
mov eax,[ebp+12] ; 2. Parameter in eax laden
...
pop ebp
ret

Flüchtige und nicht-flüchtige Register / Anbindung an C
Damit Funktionen von verschiedenen Stellen des Assemblerprogramms heraus aufgerufen werden können, ist es wichtig, festzulegen, welche Registerinhalte von der Funktion verändert werden dürfen und welche beim Verlassen der Funktion noch (oder wieder) den alten Wert besitzen müssen. Am sichersten ist es natürlich, grundsätzlich alle Register, welche die Funktion zur Erfüllung ihrer Aufgabe benötigt, zu Beginn der Funktion auf dem Stack zu speichern und unmittelbar vor Verlassen der Funktion wieder zu laden.
Die Assemblerprogramme, die der GNU-C-Compiler erzeugt, verfolgen jedoch eine etwas andere Strategie: Sie gehen davon aus, dass viele Register sowieso nur kurzfristig verwendet werden, zum Beispiel als Zählvariable von kleinen Schleifen, oder um die Parameter für eine Funktion auf den Stack zu schreiben. Hier wäre es reine Verschwendung, die ohnehin längst veralteten Werte zu Beginn einer Funktion mühsam zu sichern und am Ende wiederherzustellen. Da man einem Register nicht ansieht, ob sein Inhalt wertvoll ist oder nicht, haben die Entwickler des GNU-C-Compilers einfach festgelegt, dass die Register eax, ecx und edx grundsätzlich als flüchtige Register zu betrachten sind, deren Inhalt einfach überschrieben werden darf. Das Register eax hat dabei noch eine besondere Rolle: Es liefert den Rückgabewert der Funktion (soweit erforderlich). Die Werte der übrigen Register müssen dagegen gerettet werden, bevor sie von einer Funktion überschrieben werden dürfen. Sie werden deshalb nicht-flüchtige Register genannt.
