
Dynamic Metadata Management for Virtual-Memory Objects
- Typ der Arbeit: Bachelorarbeit
- Status der Arbeit: laufend
- Projekte: ParPerOS
- Betreuer: Alexander Halbuer, Daniel Lohmann
- Bearbeiter: Alex Alfonso Trigo

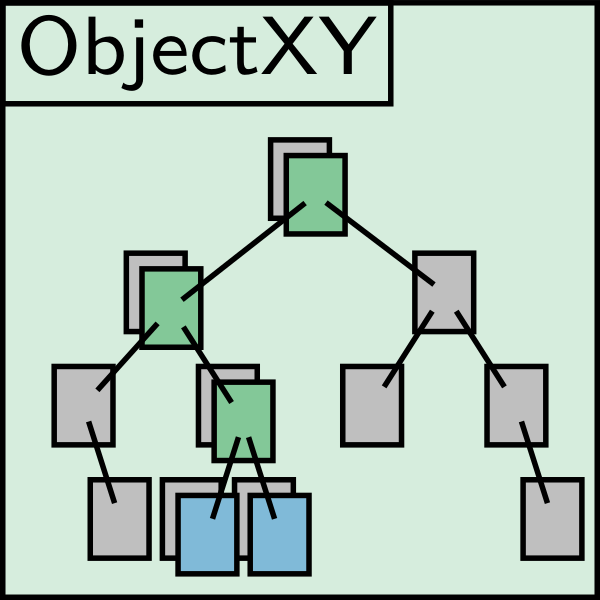
The critical path inside the page fault handler goes through the metadata hash table for reference count lookup. [Generated with AI]
Context🔗
Modern computer systems can house vast amounts of main memory, potentially heterogeneous, and offer advanced memory features such as encryption and error correction. The operating system's memory subsystem must effectively manage these diverse properties while maintaining decent performance, as it frequently resides on the critical path of program execution.
Our previous work, Morsels, introduced a novel memory-management paradigm that shifts from traditional page-based management to larger virtual-memory objects, technically represented as subtrees within the page-table hierarchy. This approach reduces management overhead and enables very fast transfer between address spaces. A key characteristic of Morsels is their self-contained design, where all necessary information is encoded directly into the page table subtree, eliminating the need for external metadata. While this design provides a clean solution, it falls short when attempting to support advanced features like copy-on-write, highlighting the need for further refinement.
Problem🔗
Linux traditionally employs a 64-byte metadata object, known as struct page, to manage each physical 4-KiB page frame.
These objects are arranged in a linear array, facilitating efficient lookups from physical addresses to associated metadata.
However, this approach has several drawbacks.
As memory management complexity increases, numerous additional properties have been introduced for page frames, but not all are necessary for all frames and at every point in time.
This has resulted in the use of nested structs and unions within struct page, creating a confusing data structure that is prone to errors.
Expanding the size of struct page would increase its already non-negligible memory overhead, which accounts for 1.6% of total memory usage.
Moreover, an uneven increase would break cache line alignment.
Currently, the 64 bytes exactly match cache line size on most architectures, preventing false sharing.
Finally, the expansion approach is not scalable with never stopping grow of additional properties.
We already started addressing this problem from different perspectives.
LLFree as allocator and Morsels as object abstraction do not require struct page for used page frames.
We demonstrated that it is possible to dynamically allocate and free struct page instances while they are not used, providing them as additional usable memory to applications (the related publications and theses are linked below).
The introduction of a copy-on-write mechanism for Morsels requires additional storage space for reference counts associated with page tables and leaf
pages.
To maintain independence from struct page, we investigated an alternative approach leveraging the Linux in-kernel hash table implementation, rhashtable.
Our prototypic implementation shows promising results, as it reduces metadata overhead by only storing reference counts when they are actually used (implicitly assuming a count of one for non-existent entries).
However, the linked-list-based layout of rhashtable incurs multiple random memory accesses in the critical path of the page fault handler when checking or resolving copy-on-write relationships.
This ultimately degrades application performance.
Additionally, the pointers within the buckets introduce extra memory overhead (a 64-bit pointer for every 64-bit counter).
In combination with the static hash table data structures, the memory savings from unused metadata can be easily outweighed by the memory-inefficient hash table implementation.
Goal🔗
The primary objective of this thesis is to quantify the runtime overhead of the hash-table-based copy-on-write implementation in different scenarios. Preliminary measurements suggest that several factors influence performance, including:
- Insertion and removal operations in the hash table
- Hash table size and utilization
- Concurrent accesses
- Ongoing resizing operations
In a second step, the performance should be improved based on the findings from step one. These can include, but is not limited to:
- Batch operations (insert, increment, decrement)
- Optimizing hash table parameters for the specific use case
- Looking for alternative implementations
One promising approach is the Rosebush data structure, which replaces linked-list bucket chaining with a more efficient design, reducing random memory accesses and potentially improving performance.
Schedule🔗
The thesis will follow these key steps:
- Getting started: Familiarize with kernel development, set up a suitable development environment, and establish a functional test setup.
- Macro benchmarking: Analyze performance of the copy-on-write features in different scenarios.
- Micro benchmarking: Isolate the hash-table implementation into a standalone user-space application to get more detailed insights into the performance of different operations under various conditions.
- Optimization: Optimize the implementation for the copy-on-write use case.
- Evaluation: Evaluate performance gains in an end-to-end scenario.
Topics: C, Linux kernel, copy-on-write, data structures, rhashtable, rosebush
References🔗
Web Links🔗
- The rhashtable documentation I wanted to read
- Rhashtables: under the hood
- Rosebush, a new hash table
Papers🔗
-
USENIX
Conference
A
Distinguished Artifact Award
LLFree: Scalable and Optionally-Persistent Page-Frame Allocation -
2023 USENIX Annual Technical Conference (USENIX '23)USENIX Association2023Distinguished Artifact Award.
PDF Details Slides [BibTex]
-
DIMES
Workshop
Morsels: Explicit Virtual Memory Objects -
Proceedings of the 1st Workshop on Disruptive Memory SystemsAssociation for Computing Machinery2023.
PDF Details Slides 10.1145/3609308.3625267 [BibTex]
Related Theses🔗
Optimizing Memory Metadata: Dynamic Allocation of Struct Pages in the Linux Kernel

- Typ
- Masterarbeit
- Status
- abgeschlossen
- Supervisors
- Lars Wrenger
Alexander Halbuer
Daniel Lohmann - Project
- ParPerOS
- Bearbeiter
- Paul Aumann (abgegeben: 14. Jun 2024)
Efficient Copy-on-Write for Virtual-Memory Objects
- Typ
- Masterarbeit
- Status
- abgeschlossen
- Supervisors
- Alexander Halbuer
Daniel Lohmann - Project
- ParPerOS
- Bearbeiter
- Pasha Fistanto (abgegeben: 02. May 2024)